ft_irc 프로젝트에서 해결하고 싶었던 네트워크 문제들을 이번에 다시 돌아보고 원인을 분석한 뒤 해결해 보고자 한다.
좀비 fd는 코드 문제
ft_irc에서 클라이언트 연결 중 와이파이가 단절되면 좀비 파일 디스크립터(정리되지 않고 남아 있는 fd)가 발생하는 문제가 있었다.
// C++98 ft_irc
void Server::deleteClient(int clientFd)
{
std::clog << "[Log] Deleteting Client " << clientFd << std::endl;
setPoll(clientFd, -1, 0, 0);
_message.erase(clientFd);
delete _clients[clientFd];
_clients.erase(clientFd);
close(clientFd);
}
당시에 C++98 제약 때문에 raw pointer를 사용했고 직접 delete를 해야 했다. 예외가 발생하거나 중간에 함수가 반환되면 delete 호출되지 않을 수 있고 메모리 누수가 발생한다. 또한 poll 루프나 deleteClient에서 비정상 종료 상황(POLLERR 등)을 처리하지 않았다.
// modern irc
void Server::removeClient(int clientFd)
{
auto it = mClients.find(clientFd);
if (it != mClients.end())
{
if (!it->second->IsMarkedForClose())
{
std::cout << "[INFO] Client fd " << clientFd << " marked for close (connection lost)" << std::endl;
it->second->MarkForClose();
}
}
}
이번 프로젝트에서는 C++98 제약이 없어 unique_ptr을 사용했다. removeClient에서 바로 erase하지 않고 MarkForClose만 설정한다. 이렇게 하면 poll 루프가 있는 곳에서 클린업 루프를 통해 안전하게 제거된다. 클린업 루프는 채널에 QUIT 메시지를 브로드캐스트하고, poll 목록에서 fd를 제거한 뒤 최종적으로 Client 객체를 소멸시킨다. 클린업 루프는 아래에서 자세히 설명한다.
// modern irc
void Server::StartServer()
{
if (revents & (POLLHUP | POLLERR))
{
removeClient(fd);
ret--;
break;
}
if (revents & POLLOUT)
{
ssize_t sent = send(fd, msg.c_str(), msg.length(), 0);
if (sent < 0)
{
if (errno == EAGAIN || errno == EWOULDBLOCK)
{
client.AddSendMessage(msg);
}
else
{
removeClient(fd);
ret--;
continue;
}
}
}
}
// modern irc
void Server::StartServer()
{
// clean up loop
for (auto it = mClients.begin(); it != mClients.end();)
{
if (it->second->IsMarkedForClose() && !it->second->HasPendingSend())
{
int fd = it->first;
std::cout << "[CLEANUP] fd=" << fd << " will be closed.." << std::endl;
if (it->second->IsAuthorized() && !it->second->GetNickname().empty())
{
mClientsByNick.erase(it->second->GetNickname());
BroadcastQuitMessage(it->second.get(), "Ping timeout");
}
it = mClients.erase(it);
mPollFds.erase(
std::remove_if(mPollFds.begin(), mPollFds.end(),
[fd](const struct pollfd& pfd) { return pfd.fd == fd; }),
mPollFds.end()
);
}
else
{
++it;
}
}
}
ft_irc에서는 없었던 클린업 루프를 만들었다. send() 실패, POLLHUP, POLLERR, PING/PONG 타임아웃 등 비정상 상황을 포함한 모든 종료 경로가 이 단일 클린업 루프로 수렴된다. 여기에서만 mClients.erase(it)을 하고 Client 소멸자에서 close(fd)를 자동 호출하게 된다.
실제로 이번 코드로 테스트 중 클라이언트를 다른 IP 주소로 바꿨을 때 에러처리를 확인할 수 있었다. 서버는 유령 클라이언트 fd를 바로 삭제하지 않는다. POLLHUP이나 POLLERR가 발생하지 않았고, recv도 0을 반환하지 않아 커널이 아직 연결이 살아있다고 판단한다. 이때 같은 채널에 있는 다른 클라이언트가 QUIT을 하면서 QUIT 메시지가 채널에 브로드캐스트되고, 유령 클라이언트 fd에 메시지를 보내려고 시도한다. 하지만 send()가 실패하면서 ECONNRESET 같은 에러가 발생하고 removeClient(fd)가 호출되어 MarkForClose가 설정된다. 이후 클린업 루프에서 깔끔하게 소멸한다. 실제로 다른 클라이언트가 QUIT을 할 때 유령 클라이언트 fd의 종료 로그가 출력된다. 유령 fd를 바로 처리하지 않고 나중에 정리해 준 것처럼 보이게 된다. 늦게 발견되더라도 결국에는 반드시 정리가 된다. 이번 리팩토링에서는 removeClient + MarkForClose + 클린업 루프로 이어지는 안전한 자원 정리 경로를 구축했다.
[예전 ft_irc]
클라이언트 종료 감지
│
├── deleteClient() 호출
│ ├── setPoll(-1) // poll 배열에서 제거
│ ├── delete _clients[] // raw pointer 직접 해제
│ ├── _clients.erase()
│ └── close(fd)
│
└── (호출되지 않으면?) → fd + 메모리 누수
--------------------------------------------
[현재 modern-irc]
클라이언트 종료 감지
│
├── removeClient() 호출
│ └── MarkForClose()
│
├── 클린업 루프
│ ├── IsMarkedForClose() && !HasPendingSend()
│ ├── mClients.erase(it)
│ │ └── ~Client() → close(fd)
│ └── mPollFds.erase()
│
└── 모든 종료 경로가 이 흐름으로 수렴 → 누수 없음
TCP Keep-Alive로 네트워크 단절 감지
위에서 fd 자원 처리를 어떻게 견고하게 만들지 고민했다면, 이번에는 네트워크 단절을 빠르게 감지해 좀비 fd가 되는 것을 방지하고 지연 시간을 줄여본다.
TCP Keep-Alive는 전송 계층(Transport Layer)에서 동작하는 메커니즘으로, 일정 시간 동안 데이터 송수신이 없는 idle connection이 실제로 살아있는지 확인하는 역할을 한다.
- 설정된 idle time동안 아무런 데이터도 오가지 않으면, 커널이 상대방에게 Keep-Alive 프로브(probe)를 전송한다.
- 상대방이 정상적으로 ACK를 보내면 연결이 유지된다.
- 일정 횟수(보통 3~5회) 동안 응답이 없으면, 커널은 해당 연결을 끊어진 것으로 판단하고 소켓을 닫는다.
이때 서버 애플리케이션에는 recv()가 0을 반환하거나, POLLHUP/POLLERR 이벤트가 발생한다. 우리 서버는 이 신호를 받아 평소처럼 removeClient()를 호출하게 된다.
// Server::addClient() 내부, accept() 이후
int optval = 1;
// 1) Keep-Alive 기능 활성화
setsockopt(clientFd, SOL_SOCKET, SO_KEEPALIVE, &optval, sizeof(optval));
// 2) macOS 전용: 첫 Keep-Alive 패킷 전송까지의 idle time (10초)
#ifdef __APPLE__
int idleTime = 10; // 10초
setsockopt(clientFd, IPPROTO_TCP, TCP_KEEPALIVE, &idleTime, sizeof(idleTime));
#endif
SO_KEEPALIVE 옵션만으로 TCP Keep-Alive 기능을 활성화할 수 있지만, 언제 첫 프로브를 보낼지는 운영체제의 기본값(보통 2시간)을 따른다. macOS에서는 TCP_KEEPALIVE 옵션을 통해 첫 Keep-Alive 패킷 전송까지의 idle time(초)을 직접 설정할 수 있다.
 Wireshark를 이용해서 TCP Keep-Alive 패킷이 실제로 전송되는 것을 확인할 수 있다.
만약 와이파이가 끊긴 클라이언트에게 이 패킷이 전송되고, 응답이 없으면 커널이 연결을 종료하게 된다.
Keep-Alive를 설정하지 않으면 서버가 종료될 때까지 네트워크 단절된 fd가 정리되지 않는다.
Wireshark를 이용해서 TCP Keep-Alive 패킷이 실제로 전송되는 것을 확인할 수 있다.
만약 와이파이가 끊긴 클라이언트에게 이 패킷이 전송되고, 응답이 없으면 커널이 연결을 종료하게 된다.
Keep-Alive를 설정하지 않으면 서버가 종료될 때까지 네트워크 단절된 fd가 정리되지 않는다.
물론 irssi로 주기적으로 서버에 PING을 보내지만, 이는 클라이언트 자신의 연결을 확인하는 용도일 뿐, 서버가 클라이언트의 무응답을 알아차리는 데는 거의 도움 되지 않는다. 서버가 주도적으로 연결 상태를 감시하려면 TCP Keep-Alive가 필요하다.
한 가지 문제는 TCP Keep-Alive는 네트워크 단절을 감지하는 데는 효과적이지만, 애플리케이션이 응답하지 않는 상황(프로세스 정지, 교착 상태 등)은 감지할 수 없다. 그리고 같은 채널 내 다른 클라이언트들이 네트워크 단절로 연결이 끊긴 클라이언트를 알 수 없다. 이런 상황을 감지하기 위해 IRC 프로토콜의 PING/PONG을 통한 애플리케이션 레벨의 헬스 체크가 필요하게 되었다.
PING/PONG의 역할
TCP Keep-Alive는 네트워크가 단절되었을 때 연결 종료를 감지하는 데 유용하지만, 다음과 같은 상황에서는 알 수 없다.
- 클라이언트 프로세스가 Ctrl+Z(SIGTSTP)로 일시 중지가 된 경우
- 클라이언트 애플리케이션이 교착 상태(deadlock)에 빠졌을 때
- 클라이언트가 의도적으로 응답하지 않는 경우
이런 상황에서 TCP 연결 자체는 살아있기 때문에, Keep-Alive만으로는 서버가 문제를 감지할 수 없다.
이를 위해 기존 PING 명령어만 있던 서버에 PONG 명령어를 추가한다. 기존 PING은 레퍼런스로 쓰는 irssi에서 주기적으로 PONG을 보내 따로 구현했다. 새로 추가하는 PONG은 서버가 능동적으로 주기적인 PING을 보내고, 응답이 없으면 연결을 종료한다. 주기적으로 명령을 보내기 위해 타이머 로직을 추가한다.
// modern irc
Server::StartServer()
{
int ret = poll(mPollFds.data(), mPollFds.size(), 1000);
// (events handling)
auto now = std::chrono::steady_clock::now();
for (auto& pair : mClients)
{
Client& client = *pair.second;
if (client.IsMarkedForClose())
continue;
if (!client.IsAuthorized())
continue;
// send ping every 30 seconds
auto timeSinceLastPing = std::chrono::duration_cast<std::chrono::seconds>(now - client.GetLastPingSentTime());
if (timeSinceLastPing >= std::chrono::seconds(30))
{
client.AddSendMessage("PING :irc.local\r\n");
client.UpdateLastPingSentTime();
}
// timeout after last pong
auto timeSinceLastPong = std::chrono::duration_cast<std::chrono::seconds>(now - client.GetLastPongReceivedTime());
if (timeSinceLastPong >= std::chrono::seconds(60))
{
std::cout << "[PING TIMEOUT] fd=" << client.GetFd() << " nick=" << client.GetNickname() << std::endl;
client.MarkForClose();
}
}
}
poll()의 마지막 인자는 int timeout(ms)이다. 마지막 인자에 1000(ms)을 주면, I/O 이벤트가 없어도 1초마다 깨어나 주기적으로 클라이언트에 PING을 전송하고 타임아웃을 검사할 수 있다.
// modern irc
void Command::handlePong()
{
mClient.UpdateLastPongReceivedTime();
}
irssi를 포함한 모든 표준 IRC 클라이언트는 PING 메시지를 수신하면, 즉시 자동으로 PONG을 서버에게 보내준다. 우리는 이 PONG을 받고 그 시간을 기록만 하면 된다. 그 후로 60초가 지나도록 또 다른 PONG이 없으면 타임아웃으로 처리한다.
14:16 -!- Shiv [misungkim@127.0.0.1] has quit [leaving]
14:18 -!- Kendall [misungkim@127.0.0.1] has left #RoyFamily [leaving]
15:09 -!- Logan [nero@127.0.0.1] has quit [Ping timeout]
추가로 타임아웃으로 연결이 끊긴 채널 멤버를 다른 멤버들이 알 수 있도록 QUIT 전용 브로드캐스트를 추가했다.
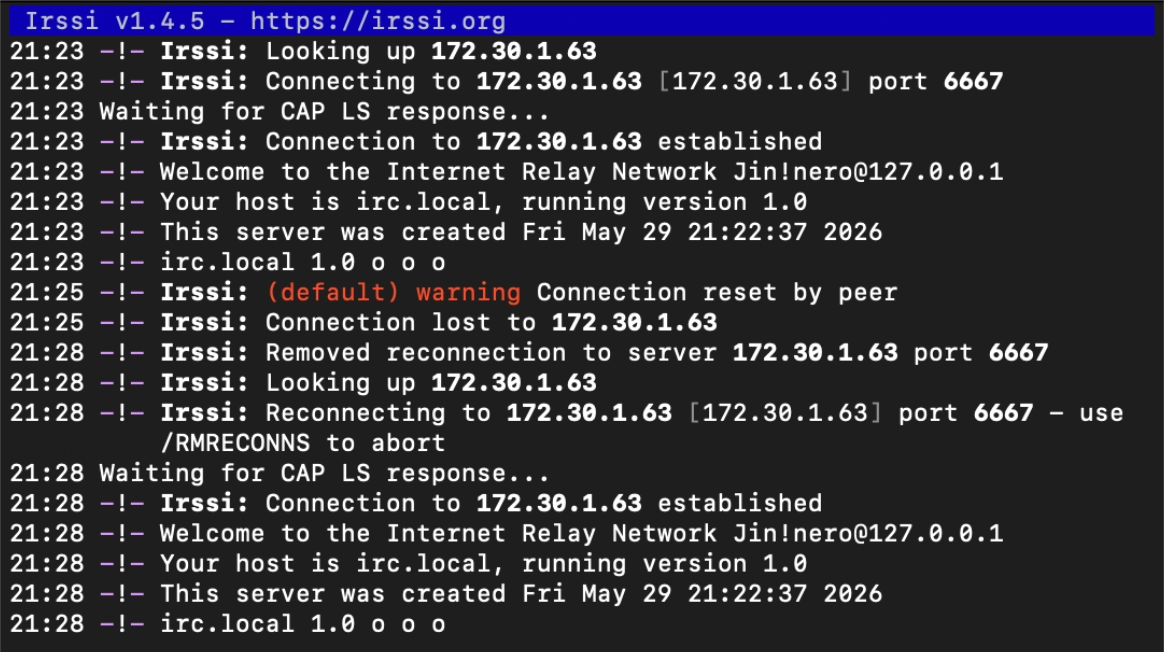 irrsi는 서버로부터 ERROR :Closing Link 신호를 받으면 "Connection lost"를 표시하고, 내장된 Auto-Reconnect 기능을 작동시킨다.
PING/PONG 로직 도입 이후 서버가 문제 있는 클라이언트를 빠르게 끊어주므로 reconnect가 더 빨라졌다.
예전에는 서버가 연결이 끊긴 걸 수 분 동안 몰랐고, 그동안 irssi도 반쯤 열린 연결(half-open) 상태에서 응답을 기다리느라 재연결을 시도하지 않았다.
irrsi는 서버로부터 ERROR :Closing Link 신호를 받으면 "Connection lost"를 표시하고, 내장된 Auto-Reconnect 기능을 작동시킨다.
PING/PONG 로직 도입 이후 서버가 문제 있는 클라이언트를 빠르게 끊어주므로 reconnect가 더 빨라졌다.
예전에는 서버가 연결이 끊긴 걸 수 분 동안 몰랐고, 그동안 irssi도 반쯤 열린 연결(half-open) 상태에서 응답을 기다리느라 재연결을 시도하지 않았다.
TCP Keep-Alive + PING/PONG 조합으로 전송 계층과 응용 계층 문제를 모두 고려한 해결 방법이 되었다.